
AVX-512 Assembly Programming: Opmask Registers for Conditional Arithmetic
This is the second installment in a continuing series of articles on Intel AVX-512 assembly programming. The first installment is An Intro to AVX-512 Assembly Programming.
Table of Contents
Problem
If you have an array (Array), that contains ArrLen signed integers, how would you find the sums of the positive and negative numbers in the array?
A Solution
Here’s an obvious solution, in C/C++:
for (int i = 0; i < ArrLen; i++) {
if (Arr[i] >= 0) PSum += Arr[i];
else NSum += Arr[i];
}This is a reasonable solution, but is it optimal? It turns out that this is a very inefficient approach, because the if … else logic makes it impossible for the processor to predict which assignment statement should be executed next. When the processor predicts incorrectly, the instruction pipeline has to be emptied, and then refilled. This results in many wasted processor cycles.
In this article, we’ll look at how AVX-512 instructions can eliminate the if…else logic, to speed up our program by at least a factor of three. As noted in the previous article, to run AVX-512 code, you must have a computer that supports this instruction set. At this time, that includes only Intel Xeon Phi processors, Intel Xeon Scalable processors, and some Intel Core-X processors.
Opmask Registers
The AVX-512 instruction set adds eight new 64-bit registers, named k0 through k7. Together with these new registers, there are a number of new instructions that set the registers and perform arithmetic and logical operations on them. This instruction set also adds many new operations that use the opmask registers to determine which computation results get written to a destination register. Since a ZMM register is 64 bytes (512 bits), the number of opmask bits needed in a particular case depends on the type of data being processed. For example, if a ZMM register contains char (byte) data, all 64 bits of an opmask register might be needed. If the ZMM register contains int or float data (four bytes = dword), only the lowest 16 bits are needed.
Setting an Opmask Register
One way to set the bits in an opmask register is to use one of the comparison instructions:
vpcmpd k1, zmm1, zmm0, 5
This instruction works on a vector, performing a packed compare of dword (32-bit integer) data. The fourth operand, 5, indicates that the comparison is “not less than.” This is one of eight possible predicates, including less than (1), equal to (0), not equal to (4), and others. These values are described in the Intel® 64 and IA-32 Architectures Software Developer’s Manual.

Fig. 1 Compare (not less than) the values in ZMM1 with those in ZMM0. Each value in ZMM1 that is not less than 0 causes a bit to be set in the k1 opmask register.
In the figure above, the vpcmpd instruction subtracts each value in ZMM0 from its paired value in ZMM1. If the result is not less than 0, the corresponding bit in k1 is set to 1. Note that although k1 has 64 bits, only the lowest 16 bits are used here.
Complement of an Opmask Register
Another useful instruction is knotw.
knotw k2, k1
The knotw instruction above negates the bits in the k1 opmask register, and stores the altered bits in the k2 opmask register. Here the k prefix signifies that this instruction operates on opmask registers — all of the instructions that modify opmask registers start with the letter k. The w suffix signifies that it operates on a word (16-bit) quantity, matching the number of values in the ZMM1 register.
With the instructions described so far, we can set one opmask register to identify which of the 16 values in a ZMM register are nonnegative (greater than or equal to 0). We can use the knotw instruction to set another opmask register to identify the negative values in the same ZMM register. This concept takes us most of the way toward being able to winnow through a mass of numbers, separating them by sign.
Addition Controlled by an Opmask Register
The final step is to use the opmask registers. To do this we’ll use an addition instruction that was newly added to the AVX-512 instruction set: vpaddd. As before, v indicates a vector instruction: the packed add of dword (32-bit integer) data.
vpaddd zmm2 {k1}, zmm0, zmm1The following figure describes the operation of this vpaddd instruction. The values in ZMM0 and ZMM1 are added, but only the values in ZMM0 with a paired value of 1 in the k1 register are written to ZMM2.
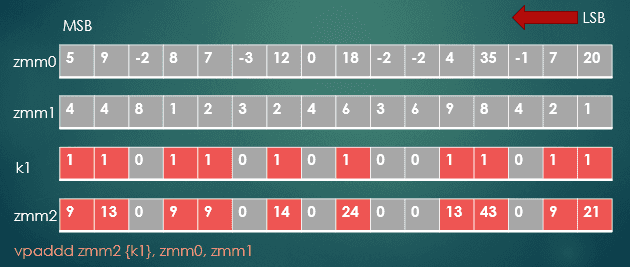
Fig. 2 Conditional addition of values from one register to another, based on the set bits in an opmask
Conditional Addition Loop
Here is some code that almost represents the C for loop at the beginning of this article.
L1:
vmovdqa32 zmm3, zmmword ptr[rdx] ; Get 16 ints from memory at address in RDX
vpcmpd k1, zmm3, zmm0, 5 ; Compare (not less than) ints in zmm3 with 0
knotw k2, k1 ; Flip the bits in k1, store in k2
vpaddd zmm1 {k1}, zmm1, zmm3 ; Add the pos. values in zmm3 to the accumulator
vpaddd zmm2 {k2}, zmm2, zmm3 ; Add the neg. values in zmm3 to the accumulator
add rdx, 64 ; Increment array address to next 16 ints
loop L1 ; Decrement loop counter RCX. If >0, go to L1You can assume that the array to be processed starts at the address in RDX, and that the number of iterations of this loop is stored in RCX, two of the Intel general purpose registers. You can also assume that the ZMM0 register is initialized to 16 int values of 0.
Line-by-line Discussion of the Loop
The first instruction, vmovdqa32, moves 16 int values (a total of 64 bytes or 512 bits) from the array into the ZMM3 register.
The second instruction, vpcmpd, which has already been discussed, compares each of the 16 int values in ZMM3 against 0. For each value that is not less than 0, the corresponding bit in k1 is set to 1, similar to what Figure 1 depicts.
The knotw instruction, has also been discussed. It complements (flips) the bits in k1 and stores them in k2.
The first vpaddd instruction adds the 16 int values in ZMM3 to those in the accumulator register, ZMM1. However, it stores only the sums for which the value in ZMM3 was greater than or equal to zero (i.e., not less than zero). Any sum that is not written has no effect on the value already in the accumulator register, ZMM1.
The second vpaddd instruction is almost exactly the same. The only difference is that it uses the k2 opmask register to pick out the negative numbers in ZMM3, adding them to a different accumulator register, ZMM2.
The add instruction adds 64 to RDX to reset it to the address of the next chunk of 16 int values.
Finally, the loop L1 instruction implicitly involves RCX. This instruction decrements RCX; if the new value is zero, control passes out of the loop. Otherwise, control flows to the L1 label.
Where We Stand Now
After the loop has processed all of the numbers in the array, the two accumulator registers, ZMM1 and ZMM2, hold 16 partial sums apiece — those of the positive values and those of the negative values.
The only remaining tasks are to combine both sets of partial sums to produce the two totals. We will resume these tasks in the second part of this article, which will also include all of the code. It will also include a comparison in the running times of the for loop at the beginning of this article, against that of the AVX-512 code presented here.
So stay tuned!
Former college mathematics professor for 19 years where I also taught a variety of programming languages, including Fortran, Modula-2, C, and C++. Former technical writer for 15 years at a large software firm headquartered in Redmond, WA. Current associate faculty at a nearby community college, teaching classes in C++ and computer architecture/assembly language.
I enjoy traipsing around off-trail in Olympic National Park and the North Cascades and elsewhere, as well as riding and tinkering with my four motorcycles.






Are there libraries that make use of this instruction set to handle arbitrary length vectors?Thanks for taking the time to have a look at my article! The conclusion of this article is in the pipeline, and should be published in a few days.
Regarding your question, not that I know of, but then I don't really know what products are using this technology. Most of my efforts have been spent in just figuring out how to use this stuff. The AVX-512 instruction set has about a dozen subsets, some of which are yet to be released. One of the yet-to-be-released subsets is AVX-512VNNI (vector neural network instructions), and is designed to accelerate convolutional neural network algorithms (https://en.wikichip.org/wiki/x86/avx512vnni).
As far as who else is using this technology, the AVX-512 stuff is pretty new, so, and makes some heavy hardward demands. I think the situation is a bit like when Intel and AMD came out with 32-bit processors in the mid-80s, but it took about 10 years for OSes to catch up.
I'm learning a lot. Thanks for sharing.
Are there libraries that make use of this instruction set to handle arbitrary length vectors?