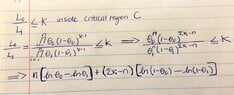- #1
mathjam0990
- 29
- 0
View attachment 5426What I have done so far...
View attachment 5427
Is this correct so far? If not, would someone be able to provide an explanation as to how to solve this? I am not sure if I am going in the right direction. Thank you
View attachment 5427
Is this correct so far? If not, would someone be able to provide an explanation as to how to solve this? I am not sure if I am going in the right direction. Thank you