- #1
evinda
Gold Member
MHB
- 3,836
- 0
Hello! (Nerd)
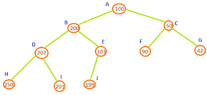
Suppose that we have this tree:
View attachment 3559
and we want to apply the following algorithm:
We call the procedures [m]Pr(A), Pr(B), Pr(D), Pr(H), Pr(NULL)[/m], right?
When we run the Procedure [m]Pr(NULL)[/m], the command [m]return;[/m] is executed.
After that, what do we have to do? Do we have to execute the commands, that are under the command [m]Pr(P->lc);[/m] for [m]P->lc=H[/m] ? (Thinking)
Suppose that we have this tree:
View attachment 3559
and we want to apply the following algorithm:
Code:
Procedure Pr(pointer P){
if (P==NULL) return;
Pr(P->lc);
print(P->data);
Pr(P->rc);
}When we run the Procedure [m]Pr(NULL)[/m], the command [m]return;[/m] is executed.
After that, what do we have to do? Do we have to execute the commands, that are under the command [m]Pr(P->lc);[/m] for [m]P->lc=H[/m] ? (Thinking)